aliases: tags: layout: post title: "张作峰 个人简历" date: 2025-06-08 23:00:00 category: JavaWeb tag: - Resume share: false comments: false
张作峰 - T12级专家、架构师
18320872958 Call me | featzhang@apache.org Mail to me | github.com/featzhang See detail
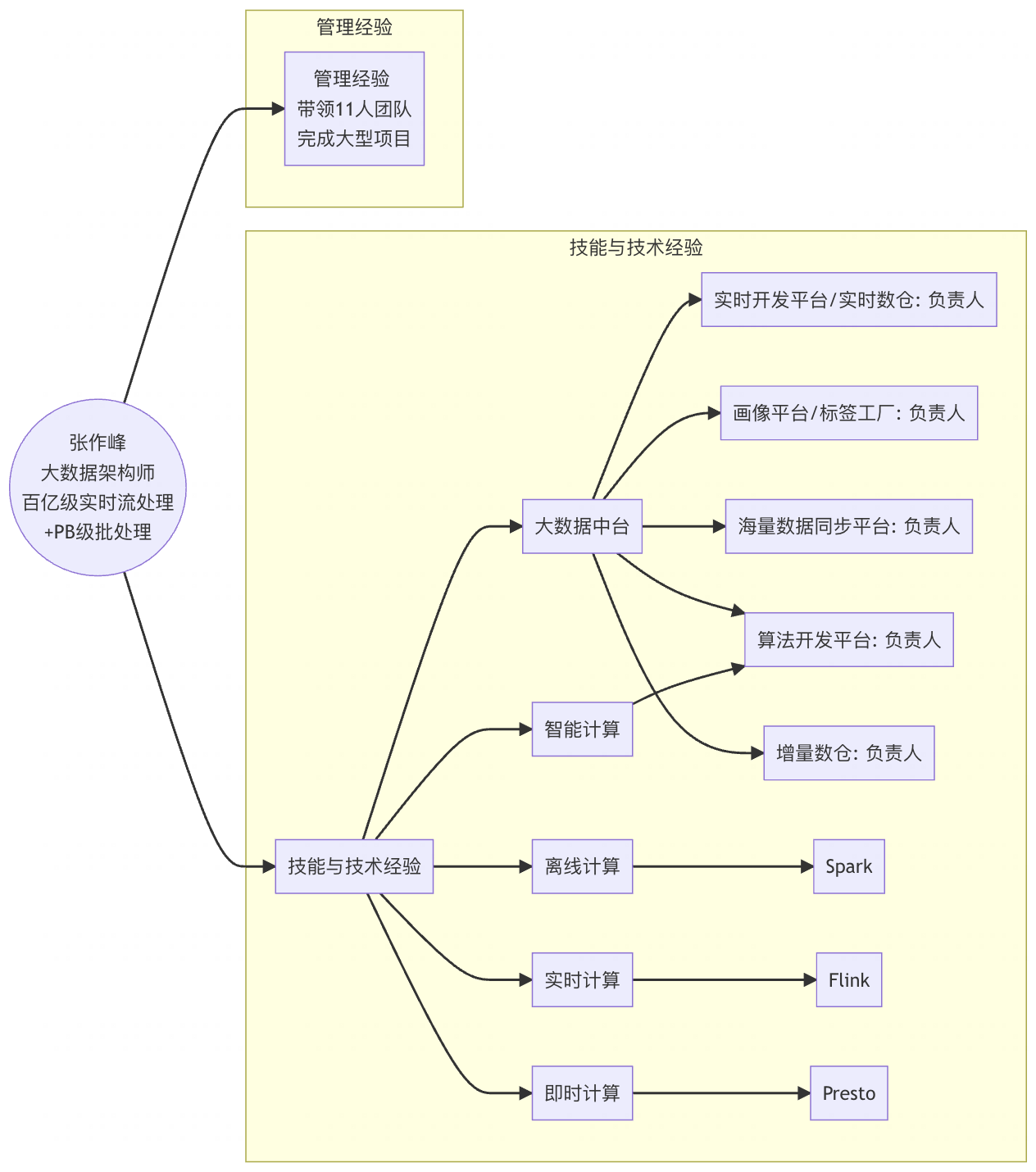
Apache InLong committer,Apache Hudi/Flink contributor,腾讯T12级大数据专家,拥有12年Java大数据开发经验。专注于千亿级实时流处理、PB级批处理和大数据中台建设,在实时计算平台架构、AI与大数据融合、金融级数据保障等领域有深厚积累。现任Oceanus(腾讯公司级Flink开发平台)负责人,带领11人技术团队。
核心技能
大数据技术栈
- 实时计算: Flink、Spark Streaming、Storm、千亿级流处理
- 数据存储: Hudi、StarRocks、Kylin、HBase、Redis、ES
- 数据处理: Spark、MapReduce、实时ETL、批流一体
平台架构能力
- 平台建设: 大数据中台、实时计算平台、数据治理体系
- AI融合: 机器学习平台、大模型算子化、智能运维
- 金融级保障: 数据一致性、高可用架构、监控体系
团队管理
- 11人团队管理、技术架构规划、项目交付管理
教育经历
- 2010.09 - 2013.06 湘潭大学 控制理论与控制工程(智能计算) 硕士研究生
- 2006.09 - 2010.06 青海大学 自动化 本科
工作经历
| 起止时间 | 公司 | 职责 |
|---|---|---|
| 2017.06 ~ 至今 | 腾讯 | 大数据(数据中台)T12专家、架构师 实时计算平台、实时数仓负责人(带领11人团队) 腾讯Flink开发平台负责人 |
| 2016.06 ~ 2017.06 | 平安科技 | 渠道联盟(广告营销平台): 开发负责人(带领5人团队) |
| 2013.07 ~ 2016.06 | 创维软件 | 电视节目推荐平台: 平台(上报、采集、计算、算法)负责人(带领4人团队) |
项目经验
腾讯实时计算平台Oceanus 2024年8月~至今
角色 平台负责人(带领6人团队)
业界头部实时计算平台,基于 Apache Flink支撑腾讯全域业务,具备低门槛、低延迟、数万并发任务处理能力,覆盖实时 ETL、风控、推荐、数仓等场景,服务金融、电商等多行业。
构建智能运维体系,实现故障预防与自动修复:
- 全链路监控:100 + 指标覆盖数据接入到输出全流程,结合 OpenTelemetry 实现可视化追踪
- AI 驱动预测:机器学习模型分析资源使用率、数据积压量,提前预警性能衰减
- 自动化治理:智能诊断引擎自动定位根因,巡检系统处理常见问题 成果:故障率下降 90%,2025H1 达成零重大故障、零投诉
打造 AI 与实时计算融合平台:
- 批流一体架构:统一调度实时流与历史批量数据处理
- Python 原生扩展:无缝集成 NumPy、TensorFlow 等 Python 生态工具
- 模型算子化(混元数据管道):将混元大模型封装为标准算子嵌入数据流,推荐场景延迟降低 60%
- 统一技术栈:一站式开发平台覆盖数据处理到模型推理全链路
极致弹性的实时在线服务:
- 零断流、超大状态的实时在线自动调整:单点快速重启、存算分离
- 零断流垂直弹性扩缩容:通过 AI 模型预测、细粒度资源管理和零断流的垂直伸缩,做到了提前感知、无损调整和自动化运维,实现了云原生场景下的极致弹性。
腾讯金融实时湖仓平台 2019年12月~2024年8月
Flink Forward Asia 2023: 《腾讯金融实时计算平台实践》 PPT

角色 : 架构师(Tech Leader)、项目负责人(带领11人团队)
一站式实时开发和治理平台, 提供了SQL、画布、Jar和拖拽式开发API, 基于Flink、Spark、MR和微服务等计算引擎. 第三方的平台可以通过SDK快速接入, 只需按照规范和协议提交参数就可以方便的创建任务, 根据实时性要求路由到不同的引擎进行调度. 基于Flink调度能力,与Hudi、StarRocks等引擎结合,构建实时ETL工具, 支撑业务50T/天的数据量.
金融级数据保障:
链路血缘分析, 基于Flink SQL流批一体对账和数据回补, 状态数据分析, 数据染色校验, 自动压测, 双链路, 任务灰度发布
智能运维:
延迟监控, 实时指标体系, 健康度评分, 自动诊断, 自动修复
增量数仓:
在实时数仓的基础上, 基于Apache hudi实现流批一体增量数仓, 解决离线任务计算瓶颈
实时大数据在线化:
实时计算能力在交易后台和C端场景的应用
特征工厂 2019年4月~2019年11月
角色: 项目负责人(带领7人团队)
统一特征计算与存储服务平台。基于 Spark SQL 和 Flink SQL 实现画像标签的配置化开发与一键部署,通过 Redis+HBase封装多模存储支持 150 亿实体 ×2 万维标签的高效管理,日均处理数据量超 10PB,覆盖 30 个业务线。核心能力包括:
- 多模特征服务:统一 API 接入,支持 KV/Table/ 非结构化数据的点查与批量更新,实现特征生产配置化;
- 事件驱动型长周期实时特征:针对周 / 月 / 年级别标签,融合计算与存储优势解决状态管理难题,保障精准产出;
- 低代码开发:集成 OLAP 引擎(如 Impala)进行交互式数据探索,通过拖拽式平台实现标签逻辑可视化定义,自动转换为 Spark/Flink SQL,降低开发门槛;
- 配置化标签整合上线: 按主题自动合并标签 SQL,通过配置化 Spark 任务生成画像宽表,减少重复计算,提升效率。多场景部署:
- 在线查询:宽表压缩为 HFile 后通过 Bulkload 写入 HBase,支持毫秒级点查。
- 离线分析:通过 Flink Batch 将数据转换为 Parquet 格式,存储至 CDH 集群,供 Impala 进行多维分析。
- 链路治理:基于血缘分析自动优化数据路径,结合数据染色与异步监控保障标签质量。
腾讯亚秒级OLAP数据分析平台 2018年6月~2019年4月
全民BI是一个一站式智能化的大数据服务平台,为用户提供自助化、智能化、平台化的数据服务能力,以及全业务链路的大数据运营分析解决方案。通过全民BI能够实现了解用户到业务分析以及最终的投放运营闭环,为打造数据中台提供基础。
基于tableau + kylin的技术创新:
结合Tableau灵活的可视化能力和Kylin(开源版)多维CUBE预处理能力, 构建的大数据分析工具. 在此过程中, 通过突破Tableau鉴权体系, 实现内部OA多用户和角色的管理;通过请求伪造等方法整合Tableau viz. 优化Kylin开源版引擎, 提升性能. 目前已经支持20余个业务和日用户增量5亿条的数据分析. Kylin和Tableau多个优化已反馈开源社区和官方.
基于ES构建PB级大数据应用:
按照业务属性、时效性要求等精细化的拆分成基础数据和多个业务数据。根据业务使用情况,预刷新底表。
机器学习算法工具化:
金融各业务场景的算法模型在系统上的沉淀和推广应用,并且能够通过数据效果反馈,不断迭代和优化我们的模型,同时实现算法模型的模板化快速生产。
金融全域数据治理体系建设:
从数据开发到运营管理以及数据质量监测的一整套管理流程来保障数据质量。数据生产各个阶段监控数据实时上报,根据数据SLA的告警自动分级分类,实现全链路任务和数据的异常发现和治理。
海量数据集成平台(FData) (2018年2月 ~ 2018年5月)
FData是一款基于Spark、MapReduce和Flink的金融级数据集成平台,支持实时海量数据的数据同步,每天可稳定高效的上线近千亿数据;针对在线服务与大数据
金融级数据保障(不丢、不重、不延迟):
完善的实时监控:支持数据同步过程中,每一步的详细监控信息。
分布式快照:借助hadoop富裕的计算资源,对数据分片,写入过程中按批Checkpoint,避免failover时重刷数据
条数对账:对数据源和目标表做实时条数对账
目标文件校验:针对HBase的HFile做文件校验,保证数据整体一致
在线存储的流量感知与过载保护
在写入标签、特征等场景中,在线存储需要同时承担高QPS的查询请求:
分布式限流:对外部存储统一管理,按照优先级和调度时间分配写入流量。
存储流量感知:在写入数据时实时,对数据预压缩、实时统计写入速度,集群级别分布式限速。
高效配置:配置 + 插件两种方式
丰富且可扩展的Connector: 不依赖特定执行引擎,基于通用API快速扩展新存储引擎。
丰富且可扩展的Format:支持常见的数据序列化格式,支持写入加解密;简单易用的插件工具,支持自定义扩展序列化格式。
字段映射:支持通过正则表达式设置字段映射计算
Polar精准推荐平台 2017年6月~2018年1月
基于金融大数据和AI算法打造的智慧数据服务。利用金融用户画像和机器学习算法,Polar通过SaaS实时推荐引擎的方式将数据能力、模型能力直接集成到业务的各类精细化运营场景中,真正赋能业务实现千人千面和智能运营。如理财通基金推荐、自选股资讯推荐、话费充值增值服务推荐、城市服务banner广告等。
平安“渠道联盟”广告推荐系统 2016年5月~2017年5月
打通平安公司内外部的各个渠道, 引入外部ADX流量, 对接平安系近2000款APP和PC的广告位, 借助人工智能和大数据, 提高广告转化率的广告营销平台. 在项目中主要解决了业务自动化接入、在线预测工程化实现、算法服务的动态部署、画像整合与快速上线等难点. 通过Storm计算实时推荐效果. 曝光量超过10亿次, 累计用户超过5亿.
职责:架构设计, 推荐大数据平台设计、搭建和应用开发, 后台开发, 10亿级数据写入, 实时效果统计